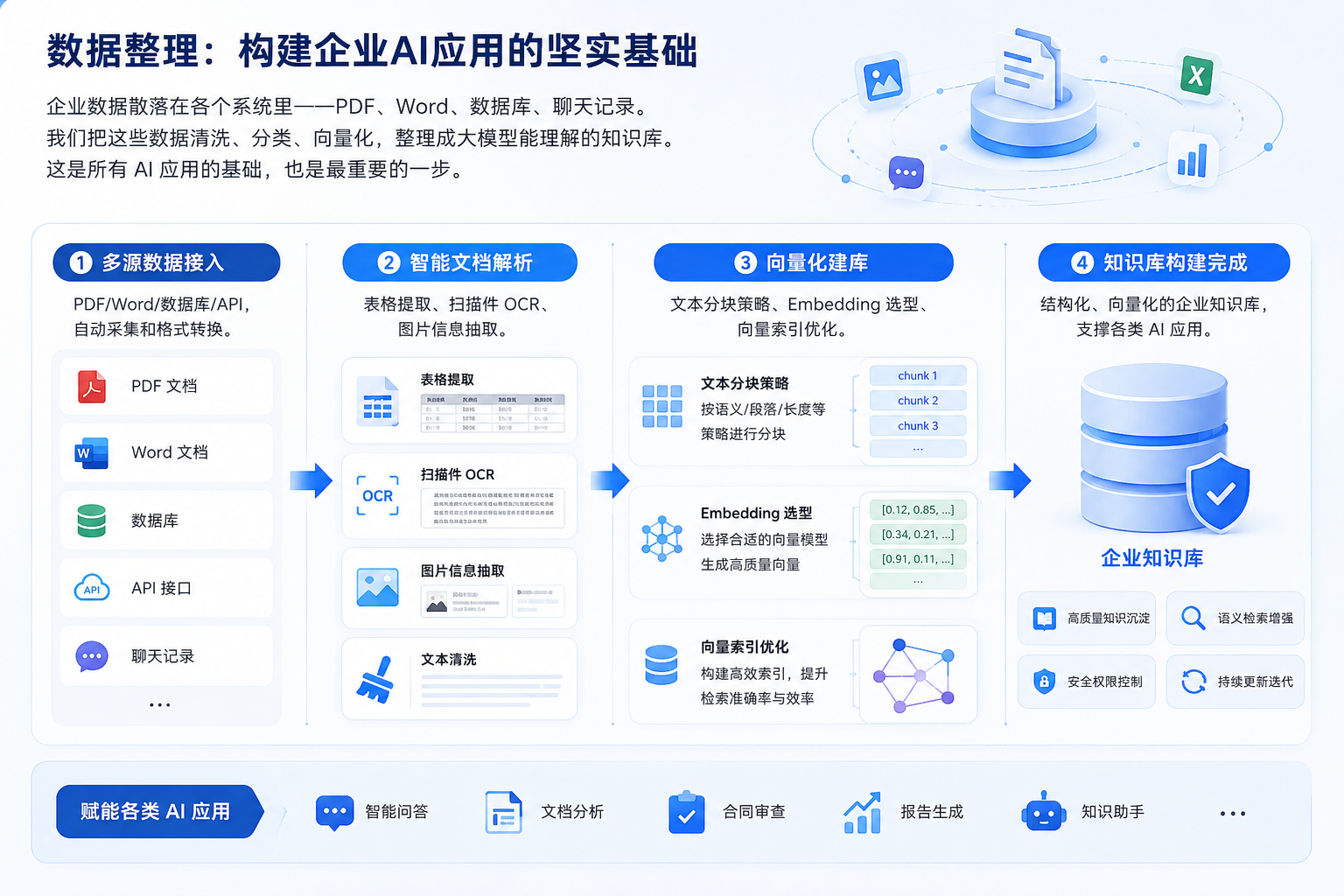
AI 工作流改造
很多企业上来就问"用什么模型、买什么硬件",但真正该先问的是"哪些事值得用 AI 做"。 我们花最多时间的事不是写代码,而是坐下来理解你的业务怎么运转的——哪些环节在反复做、哪些决策依赖经验、哪些信息流动不畅。 找到正确的问题,比急着上方案重要得多。
业务流程梳理
逐一拆解日常操作,标记重复性高、规则明确、信息密集的环节。
自动化机会评估
判断哪些流程值得 AI 化、哪些保持人工更合理,给出投入产出估算。
新工作流设计
不是简单地把人工步骤转成 AI 步骤,而是重新设计整个工作方式——人和 AI 各做擅长的部分。